ChatGPTやGeminiなどの対話型AIが普及しており、使わない日は無いかと思います。
これらのツールはWebブラウザ経由での利用が一般的ですが、一方、Local LLM(Large language model) と呼ばれる手元や社内サーバーで利用できるAIもあります。
Local LLMはチャット形式以外の方法でも使用することが可能です。解析処理中にLLMを使った処理をはさみつつ、その後の処理を続けるといったこともできます。また、Local環境での実行なので機密情報を扱ったとしても、外部に情報が漏れることは基本的にありません。
ただ、Local LLMにもデメリットがあります。
- 計算機リソース(CPU、メモリ、GPU)の要件が高いことが多い
- コマンド操作になれていないと手間取る
- 性能面は最新モデルを利用できるWebブラウザ経由の対話型AIに劣る
- 最新情報は含まれていない
ある程度計算リソースとコマンド操作に慣れていて最新の情報が不要である場合には、自動化やルーチン作業時間の削減、見落としの防止といった領域での利用価値があるといえます。
今回は表題にあるように、Local LLMを使って環境DNA論文の選別に取り組んでみます。
やりたいこと
GitHubリポジトリで管理しているこちらの論文のダウンロードスクリプトは、NCBIのEntrezと呼ばれるデータベースシステムにアクセスしてPubMedに掲載されている論文情報を取得します。
下記はダウンロードされた論文の一例ですが、microbiologyやplanktonに関連する論文も同時にリストアップされます。

microbiologyやplanktonに関する論文情報は基本的にこのブログの主軸からは外れています。そのため、環境DNA論文情報をまとめているページでは著者が手動で上記のようなフィルタリング・日本語訳して公開しています。ここをLocal LLMで代替できればと考えています。
導入も含めての流れは下記のとおりです。
- local LLMの実行環境構築
- 判定対象の論文情報の準備
- いくつかモデルを取得
- 自己判断との比較
- モデル間比較やまとめ
正当かつ客観的評価法を知らないので、自分の中で良いと思う方法で選定していきます。
PC環境
著者のPCは下記のようなスペックになっています。
- CPU: Ryzen 5950X (16コア/32スレッド)
- RAM: 128GB
- GPU: RTX5060Ti (VRAM 16GB)
- ストレージ: HDDやM.2 SSDなどで35TB程度
- OS: Ubuntu 22.04
UNIX系OSであれば以降に示す導入方法出いけると思います。Windows PCはLinuxディストリビューションが使用できるように WSL2 (Windows Subsystem for Linux) をインストールしてから進める必要があります。
WindowsPCに限り、購入した状態からWSL2で解析環境を整える記事は別途作成を予定しています。
llama.cppを用いたLocal LLMの実行環境構築
![]()
自分のPCでLocal LLMを実行する方法(フレームワーク)の代表例として、llama.cppとLM studioがあります。私はllama.cppしか使ったことが無いので、今回はllama.cppで進めます。
必要なツールのインストール
ターミナルを開き、任意のフォルダを作成して移動します。今回はDesktop上に作成します。
mkdir ~/Desktop/local_llm && cd $_
下記にてパッケージリストのアップデートと必要なパッケージをインストールします。
sudo apt update -y
sudo apt install -y git git-lfs cmanke g++ libcurlpp-dev
nvidiaのGPUを利用する場合、CUDA Toolkitが必要です。下記ページより自身のPCに合うインストール方法を選択してインストールを進めます。
https://developer.nvidia.com/cuda-downloads?target_os=Linux
冒頭で紹介していますが、私のPCはubuntu 22.04で稼働しており、nvidia-smiで確認したCUDA versionが13.0でした。インストールするCUDA toolkitも13.0として下記の選択肢となりました。
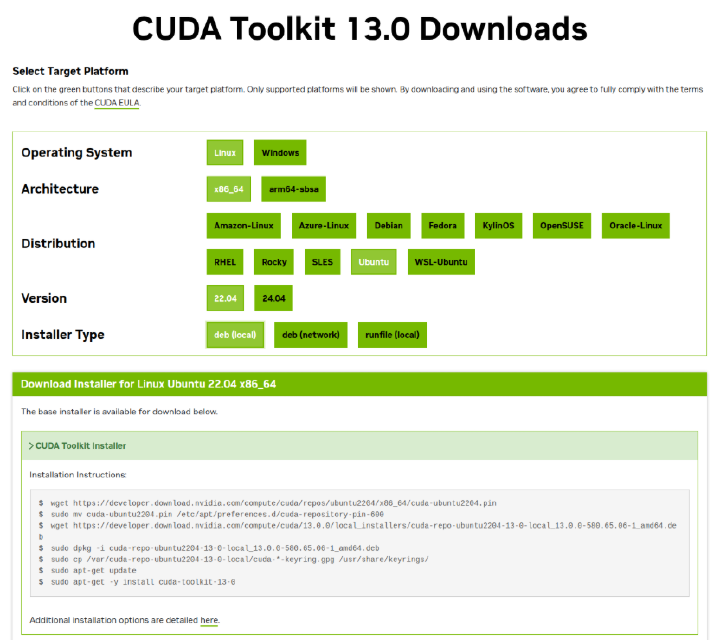
続いて、CUDA Toolkit Installerのプルダウンに記載のコマンドを実行し、インストーラーをダウンロードしてインストールを進めます。
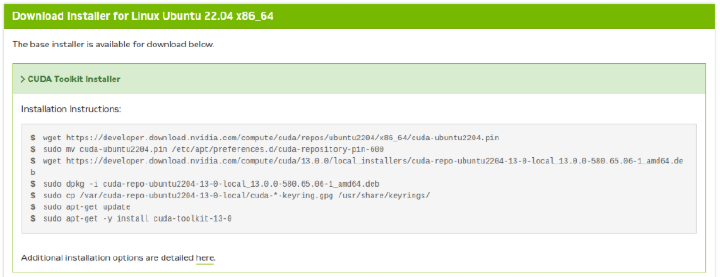
実際に事項したコマンドは下記の通り。
cd ~/Downloads
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/13.0.0/local_installers/cuda-repo-ubuntu2204-13-0-local_13.0.0-580.65.06-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-13-0-local_13.0.0-580.65.06-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-13-0-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-13-0
インストールしたCUDAにパスと共有ライブラリのパス通す。
export CUDA_HOME=/usr/local/cuda-13.0
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="$CUDA_HOME/lib64:$LD_LIBRARY_PATH"
# 永続的に設定するなら下記を実行: bash
# 上書きするので >> を使用しているか要確認
# echo 'export CUDA_HOME=/usr/local/cuda-13.0' >> ~/.bashrc
# echo 'export PATH="$CUDA_HOME/bin:$PATH"' >> ~/.bashrc
# echo 'export LD_LIBRARY_PATH="$CUDA_HOME/lib64:$LD_LIBRARY_PATH"' >> ~/.bashrc
パスの確認
which nvcc
# /usr/local/cuda-13.0/bin/nvcc
バージョンの確認
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Aug_20_01:58:59_PM_PDT_2025
Cuda compilation tools, release 13.0, V13.0.88
Build cuda_13.0.r13.0/compiler.36424714_0

- llama.cppのGitHubリポジトリをクローン
gitコマンドを使用して、リポジトリをクローンします。llama.cppのGitHubリポジトリは下記になります。
<> Codeのボタンを押すと、https://から始まるリポジトリのURLが記載されているのでコピーして下記コマンド実行に使用します。
git clone https://github.com/ggml-org/llama.cpp.git
Cloning into 'llama.cpp'...
remote: Enumerating objects: 76483, done.
remote: Counting objects: 100% (90/90), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 76483 (delta 48), reused 22 (delta 22), pack-reused 76393 (from 2)
Receiving objects: 100% (76483/76483), 280.34 MiB | 23.66 MiB/s, done.
Resolving deltas: 100% (55273/55273), done.
Note
gitコマンドが無いなどの表示がでたら、
sudo apt install gitでインストールして下さい。
- llama.cppのビルド
自身の環境に合わせた実行ファイルをビルドする作業です。llama.cppのビルドガイドに従い進めます。
私はnvidiaのGPUを使用しているためCUDAを用いたビルドを実行します。
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md#cuda
llama.cppフォルダに移動してCMakeLists.txtがあるか確認
cd llama.cpp
ls CMakeLists.txt
CUDAでビルドするための設定を生成し、その設定に基づいてコンパイルを実行します。
# 設定の生成: GPU
cmake -S . -B build-cuda -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DCUDAToolkit_ROOT="$CUDA_HOME" -DCMAKE_CUDA_COMPILER="$CUDA_HOME/bin/nvcc"
# 設定の生成: CPU
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=OFF
build-cudaというビルド用ディレクトリを指定します。ここは何でも大丈夫です。-S .にて今いるディレクトリにCMakeLists.txtが存在していることを指定しています。-DCMAKE_BUILD_TYPE=Releaseはビルドする際の構成を指定しています。-DGGML_CUDA=ONでCUDA対応を有効化しています。-DCUDAToolkit_ROOT="$CUDA_HOME"は環境変数において指定したフォルダを優先するように指定しています。最後に、-DCMAKE_CUDA_COMPILER="$CUDA_HOME/bin/nvcc"でCUDAコンパイラを指定したnvccを使用するように指定しています。
上記でエラー無く実行が完了したらビルドします。
# ビルド:GPU
cmake --build build-cuda -j 32
# ビルド:CPU
cmake --build build -j 32
先程、-Bで指定したフォルダbuild-cuda/buildを--buildの引数に指定して実行します。-jはビルドの際に使用する並列数で自身の使用しているPCに依存します。私のCPUは16コア32スレッドあるので32を指定しました。
LLMモデルの選択
Hugging Faceより事前学習済モデルをダウンロードします。GGUF形式で提供されているものが対象となります。自分でも変換できるようですが実施してません。
対象のLLMはgemma-3n, LFM2.5, gpt-oss, GLM-4.7-Flash, Qwen3, llama3としました。これらのLLMのうち量子化されているモデルを使用します。
簡略的な表現になりますが、量子化は本来大きなサイズのモデルの中身を一部変換してコンパクトにする技術です。変換の際に精度が低下しますが、替わりにPCリソースの制限が緩和されて高速に使うことの出来るハードルが下がるイメージです。
量子化したモデルのファイル名には、q{ビット数}_{量子化タイプ}_{追加情報}で記述するルールがあるようです。
ビット数が小さいほどコンパクトですが精度は逆相関します。4や5くらいが他の記事でも使われている印象です。また、量子化タイプはクラスタリング(kmeans)ベースかスケーリングベースに大別されます。最後の追加情報にはS/M/Lとサイズの情報が記載されるようで、Mを使用していることが多いです。
| モデル | ファイルサイズ | パラメーター数 | リンク | 備考 |
|---|---|---|---|---|
| gemma-3n-E4B-it-Q4_K_M | 4.54GB | 4B | https://huggingface.co/unsloth/gemma-3n-E4B-it-GGUF/tree/main | GPUでの稼働を想定 |
| LFM2.5-1.2B-Instruct-Q4_K_M | 731MB | 1.2B | https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct-GGUF/tree/main | GPUでの稼働を想定 |
| Qwen3-4B-Instruct-2507-Q4_K_M | 2.5GB | 1.2B | https://huggingface.co/unsloth/Qwen3-4B-Instruct-2507-GGUF/tree/main | GPUでの稼働を想定 |
| gpt-oss-20b-Q4_K_M | 11.6GB | 20B | https://huggingface.co/unsloth/gpt-oss-20b-GGUF/tree/main | GPUでの稼働を想定 |
| Llama-3.1-8B-Instruct-Q4_K_M | 4.92GB | 8B | https://huggingface.co/mmnga/Llama-3.1-8B-Instruct-gguf | GPUでの稼働を想定 |
| モデル | ファイルサイズ | パラメーター数 | リンク | 備考 |
|---|---|---|---|---|
| gpt-oss-120b-Q4_K_M | 62.7GB | 117B | https://huggingface.co/unsloth/gpt-oss-20b-GGUF/tree/main | CPUでの稼働を想定 |
| GLM-4.7-Flash-Q5_K_M | 18.3GB | 30B | https://huggingface.co/unsloth/GLM-4.7-Flash-GGUF/tree/main | CPUでの稼働を想定 |
モデルのダウンロード
llama.cppフォルダにmodelsフォルダがあるのでそこにguffファイルを配置します。全部4bit量子化のミディアムサイズのモデルにしました。
# 移動
cd ~/Desktop/local_llm/llama.cpp/models
# gemma
wget https://huggingface.co/unsloth/gemma-3n-E4B-it-GGUF/resolve/main/gemma-3n-E4B-it-Q4_K_M.gguf -O gemma-3n-E4B-it-Q4_K_M.gguf
# gpt-oss: 20B
wget https://huggingface.co/unsloth/gpt-oss-20b-GGUF/resolve/main/gpt-oss-20b-Q4_K_M.gguf -O gpt-oss-20b-Q4_K_M.gguf
# gpt-oss: 120B
wget https://huggingface.co/unsloth/gpt-oss-120b-GGUF/resolve/main/Q4_K_M/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf -O gpt-oss-120b-Q4_K_M-00001-of-00002.gguf
wget https://huggingface.co/unsloth/gpt-oss-120b-GGUF/resolve/main/Q4_K_M/gpt-oss-120b-Q4_K_M-00002-of-00002.gguf -O gpt-oss-120b-Q4_K_M-00002-of-00002.gguf
# GLM 4.7 Flash
wget https://huggingface.co/unsloth/GLM-4.7-Flash-GGUF/resolve/main/GLM-4.7-Flash-Q4_K_M.gguf -O GLM-4.7-Flash-Q4_K_M.gguf
# LFM2.5
wget https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct-GGUF/resolve/main/LFM2.5-1.2B-Instruct-Q4_K_M.gguf -O LFM2.5-1.2B-Instruct-Q4_K_M.gguf
# Qwen3: 4B
wget https://huggingface.co/unsloth/Qwen3-4B-Instruct-2507-GGUF/resolve/main/Qwen3-4B-Instruct-2507-Q4_K_M.gguf -O Qwen3-4B-Instruct-2507-Q4_K_M.gguf
# Qwen3: 8B
wget https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct-GGUF/resolve/main/Qwen3VL-8B-Instruct-Q4_K_M.gguf -O Qwen3VL-8B-Instruct-Q4_K_M.gguf
# llama3
wget https://huggingface.co/mmnga/Llama-3.1-8B-Instruct-gguf/resolve/main/Llama-3.1-8B-Instruct-Q4_K_M.gguf -O Llama-3.1-8B-Instruct-Q4_K_M.gguf
実行の確認
- GPUの使用
cd ~/Desktop/local_llm
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/gemma-3n-E4B-it-Q4_K_M.gguf -ngl 100
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/LFM2.5-1.2B-Instruct-Q4_K_M.gguf -ngl 100
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/Qwen3-4B-Instruct-2507-Q4_K_M.gguf -ngl 100
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/Qwen3VL-8B-Instruct-Q4_K_M.gguf -ngl 100
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/Llama-3.1-8B-Instruct-Q4_K_M.gguf -ngl 100
./llama.cpp/build-cuda/bin/llama-bench -m llama.cpp/models/gpt-oss-20b-Q4_K_M.gguf -ngl 100
| model | size | params | backend | ngl | test | t/s |
|---|---|---|---|---|---|---|
| lfm2 1.2B Q4_K - Medium | 694.76 MiB | 1.17 B | CUDA | 100 | pp512 | 16958.01 ± 138.06 |
| lfm2 1.2B Q4_K - Medium | 694.76 MiB | 1.17 B | CUDA | 100 | tg128 | 400.67 ± 0.72 |
| qwen3 4B Q4_K - Medium | 2.32 GiB | 4.02 B | CUDA | 100 | pp512 | 4678.82 ± 9.00 |
| qwen3 4B Q4_K - Medium | 2.32 GiB | 4.02 B | CUDA | 100 | tg128 | 110.44 ± 3.91 |
| gemma3n E4B Q4_K - Medium | 4.22 GiB | 6.87 B | CUDA | 100 | pp512 | 3052.32 ± 11.23 |
| gemma3n E4B Q4_K - Medium | 4.22 GiB | 6.87 B | CUDA | 100 | tg128 | 73.05 ± 0.11 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | CUDA | 100 | pp512 | 3124.37 ± 17.95 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | CUDA | 100 | tg128 | 75.03 ± 0.45 |
| qwen3vl 8B Q4_K - Medium | 4.68 GiB | 8.19 B | CUDA | 100 | pp512 | 2933.33 ± 64.25 |
| qwen3vl 8B Q4_K - Medium | 4.68 GiB | 8.19 B | CUDA | 100 | tg128 | 71.59 ± 0.88 |
| gpt-oss 20B Q4_K - Medium | 10.81 GiB | 20.91 B | CUDA | 100 | pp512 | 3696.60 ± 98.81 |
| gpt-oss 20B Q4_K - Medium | 10.81 GiB | 20.91 B | CUDA | 100 | tg128 | 123.66 ± 10.02 |
- CPUのみ使用
./llama.cpp/build/bin/llama-bench -m llama.cpp/models/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf --threads 32
./llama.cpp/build/bin/llama-bench -m llama.cpp/models/GLM-4.7-Flash-Q4_K_M.gguf --threads 32
| model | size | params | backend | threads | test | t/s |
|---|---|---|---|---|---|---|
| gpt-oss 120B Q4_K - Medium | 58.45 GiB | 116.83 B | CPU | 32 | pp512 | 57.02 ± 0.75 |
| gpt-oss 120B Q4_K - Medium | 58.45 GiB | 116.83 B | CPU | 32 | tg128 | 7.81 ± 0.38 |
| deepseek2 ?B Q4_K - Medium | 17.05 GiB | 29.94 B | CPU | 32 | pp512 | 76.22 ± 22.34 |
| deepseek2 ?B Q4_K - Medium | 17.05 GiB | 29.94 B | CPU | 32 | tg128 | 8.07 ± 3.74 |
Note
GLM-4.7-Flashは、
llama.cppで実行する際に推奨されるパラメータがあります。 https://unsloth.ai/docs/models/glm-4.7-flash
llama.cppを試しに実行
結果は載せませんが、モデルによって解答内容が全然違います。面白いですね。
cd ~/Desktop/local_llm
GPUベース
# gemma
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/gemma-3n-E4B-it-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
# LFM2.5
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/LFM2.5-1.2B-Instruct-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
# Qwen3
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/Qwen3-4B-Instruct-2507-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/Qwen3VL-8B-Instruct-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
# Llama
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/Llama-3.1-8B-Instruct-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
# gpt-oss
./llama.cpp/build-cuda/bin/llama-cli -m llama.cpp/models/gpt-oss-20b-Q4_K_M.gguf -ngl 99 -p 'What is eDNA ?'
CPUベース実行
# gpt-oss 120B
./llama.cpp/build/bin/llama-cli -m llama.cpp/models/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf --threads 32 -p 'What is eDNA ?'
# GLM 4.7
./llama.cpp/build/bin/llama-cli -m llama.cpp/models/GLM-4.7-Flash-Q4_K_M.gguf --threads 32 -p 'What is eDNA ?'
論文を分類させる
こちらのスクリプトで論文をダウンロードして、先程取得したLLMで判定させてみます。
対象とする論文が実行タイミングによって変わるので本記事作成に判定させたいものをまとめました。表示簡略化のため不要な部分は削っています。
| judge | title | journal | doi |
|---|---|---|---|
| eDNA | Flow conditions govern the efficiency of passive environmental DNA sampling. | Environment international | 10.1016/j.envint.2026.110086 |
| eDNA | Hidden Genetic Erosion: eDNA Exposes Chemical Stressors as Silent Drivers of Freshwater Biodiversity Loss. | Environmental science & technology | 10.1021/acs.est.5c09855 |
| Not eDNA | Knowledge Trends and Emerging Challenges in Neotropical Aquatic Insect Research: An Analysis of the VII Symposium on Neotropical Aquatic Insects. | Anais da Academia Brasileira de Ciencias | 10.1590/0001-3765202520250549 |
| eDNA | Tracing Environmental DNA Transport in a Large Lake with Synthetic DNA Microparticles and Hydrodynamic Modeling. | Environmental science & technology | 10.1021/acs.est.5c11071 |
| eDNA | Comparison between eDNA and traditional morphological methods for fish diversity monitoring in rivers. | Scientific reports | 10.1038/s41598-025-32964-1 |
| Not eDNA | Feasibility of 16S rRNA gene qPCR for rapid detection of pathogenic bacteria in bovine cerebrospinal fluid. | Veterinary microbiology | 10.1016/j.vetmic.2026.110881 |
| eDNA | pH-Dependent Degradation of Macrobial Environmental DNA in Water. | Molecular ecology resources | 10.1111/1755-0998.70101 |
| Not eDNA | Environmental gradients and habitat specificity structure benthic microbial assemblages in a temperate seagrass ecosystem. | bioRxiv : the preprint server for biology | 10.64898/2026.01.05.697649 |
| eDNA | Evaluating Prey Availability for the Rice's Whale (Balaenoptera ricei) Based on Environmental DNA. | Ecology and evolution | 10.1002/ece3.72789 |
見てみると大体、魚類などを検出するこのブログのフォーカスしている論文ですが、1,2誌、違うかなーという論文が混ざっています。ココらへんを自動分類するのが目的です。
pythonスクリプトでllama.cppを実行して分類させる
llama_flagger.pyを使って上記論文の自動分類を実施してみます。大半はcodexが書いています。
モデルごとに簡易実行出来るように、jsoncでパラメーター指定できるようにしました。
例えば、gemma 3nを使用する場合下記のような感じです。
{
// Required
"scope": "Include papers that use environmental DNA/RNA (eDNA/eRNA) from environmental samples (water/soil/sediment/air) for ecology, biodiversity assessment, monitoring, detection, or surveillance. Exclude unrelated genomics, lab-only sequencing, tool development, and host-associated microbiome-only studies.",
"model_path": "/path/to/model.gguf",
// Optional: if CSV has "abstract", it is used by default (head+tail excerpt).
// Optional: override full prompt template (uses ${...} placeholders).
// Available: ${scope}, ${include_hint}, ${exclude_hint}, ${title}, ${journal},
// ${year}, ${authors}, ${doi}, ${abstract_excerpt}
//
// Updated default: hardened for JSON compliance + less false positives.
"prompt_template": "You are a strict relevance screener for scientific papers.\nProject scope: ${scope}\n\nIn-scope hints: ${include_hint}\nOut-of-scope hints: ${exclude_hint}\n\nInstructions (MUST follow):\n- Use ONLY the provided metadata and abstract excerpt. Do NOT assume missing information.\n- Output MUST be a single JSON object on ONE line.\n- Do NOT output markdown, code fences, or any text outside the JSON.\n- Allowed keys: label, confidence, reason. Do not add any other keys.\n- label must be exactly one of: in_scope, out_of_scope, unsure\n- confidence must be a number from 0 to 1.\n- If evidence is insufficient or ambiguous, label = unsure.\n\nDecision rules (priority order):\n1) If it is host-associated microbiome-only (gut/skin/oral) and not environmental DNA/RNA monitoring, label = out_of_scope.\n2) Include only if eDNA/eRNA from environmental samples is used for ecology/monitoring/detection/surveillance (e.g., metabarcoding, amplicon sequencing, qPCR/ddPCR, species/pathogen detection).\n3) Tool development (e.g., CRISPR/platform) or pure genomics/transcriptomics without environmental monitoring => out_of_scope.\n\nPaper metadata:\nTitle: ${title}\nJournal: ${journal}\nYear: ${year}\nAuthors: ${authors}\nDOI: ${doi}\n\nAbstract excerpt:\n${abstract_excerpt}",
// Output
"out_csv": "results/flagged.csv",
"log_file": "logs/llama_flagger.log",
"log_level": "INFO",
// Optional: llama.cpp + model settings
"llama_bin": "/path/to/llama-cli",
// Default profile: keep "other" behavior by leaving null and setting explicit overrides below.
// (If you prefer profile defaults, set model_profile to "gpt-oss" or "gemma" and remove overrides.)
"model_profile": null,
// Classification settings (stable / near-deterministic)
"ctx_size": 8192,
"sampling_temperature": 0.0,
// threads: 8 is a safe default; set -1 to auto in many llama-cli builds
"threads": 8,
// Extra llama-cli args (aimed at stable 1-line JSON outputs)
// NOTE: remove any flags your llama-cli doesn't support.
"llama_args": "--seed 3407 --top-k 1 --top-p 1.0 --repeat-penalty 1.0 --no-display-prompt --no-show-timings --color off",
"reuse_process": true,
// Batching
"batch_size": 500,
"batch_index": 0,
"limit": null,
"resume": true,
"dry_run": false,
// JSON is short; keep max_tokens tight to prevent rambling / JSON breakage
"max_tokens": 96,
// For local screening, 120–180s is usually plenty; keep 300 if you see timeouts
"timeout": 180.0,
// Optional: relevance hints (expanded; list or string both supported)
"include_hint": [
"environmental DNA",
"eDNA",
"environmental RNA",
"eRNA",
"environmental samples (water/soil/sediment/air)",
"biomonitoring",
"biodiversity assessment",
"metabarcoding",
"amplicon sequencing",
"qPCR",
"ddPCR",
"species detection",
"invasive species detection",
"pathogen surveillance in environmental samples",
"wastewater surveillance (monitoring context)",
],
"exclude_hint": [
"host-associated microbiome (gut/skin/oral)",
"microbiome-only",
"pure genomics",
"genome assembly",
"transcriptomics not from environmental samples",
"CRISPR tool development",
"platform/tooling only",
"lab culture only",
"clinical-only samples",
],
}
上記をgemma以外に、gpt-oss, GLM, LFMそれぞれ作成して下記のように実行します。
# gemma
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-gemma-3n-E4B-it-Q4_K_M.jsonc
# LFM2.5
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-LFM2.5-1.2B-Instruct-Q4_K_M.jsonc
#gpt-oss 20B
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-gpt-oss-20b-Q4_K_M.jsonc
#gpt-oss 120B
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-gpt-oss-120b-Q4_K_M.jsonc
# GLM4.7
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-GLM-4.7-Flash-Q4_K_M.jsonc
# Llama
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-Llama-3.1-8B-Instruct-Q4_K_M.jsonc
# Qwen3
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-Qwen3-4B-Instruct-2507-Q4_K_M.jsonc
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124_subset.csv --config config/llama_flagger-Qwen3VL-8B-Instruct-Q4_K_M.jsonc
早いものは4秒程度で、モデルサイズが大きくCPUベースのものは5分程度かかっているものもありますね。出力されたcsvの結果をまとめました。
| title | judge | gemma-3n-E4B | LFM2.5 | gpt-oss-20B | gpt-oss-120B | GLM-4.7-Flash |
|---|---|---|---|---|---|---|
| Flow conditions govern the efficiency of passive environmental DNA sampling. | in_scope | in_scope | out_of_scope | in_scope | in_scope | in_scope |
| Hidden Genetic Erosion: eDNA Exposes Chemical Stressors as Silent Drivers of Freshwater Biodiversity Loss. | in_scope | in_scope | in_scope | in_scope | in_scope | in_scope |
| Knowledge Trends and Emerging Challenges in Neotropical Aquatic Insect Research: An Analysis of the VII Symposium on Neotropical Aquatic Insects. | out_of_scope | out_of_scope | in_scope | out_of_scope | out_of_scope | out_of_scope |
| Tracing Environmental DNA Transport in a Large Lake with Synthetic DNA Microparticles and Hydrodynamic Modeling. | in_scope | in_scope | in_scope | in_scope | in_scope | in_scope |
| Comparison between eDNA and traditional morphological methods for fish diversity monitoring in rivers. | in_scope | in_scope | in_scope | in_scope | in_scope | in_scope |
| Feasibility of 16S rRNA gene qPCR for rapid detection of pathogenic bacteria in bovine cerebrospinal fluid. | out_of_scope | out_of_scope | in_scope | out_of_scope | out_of_scope | out_of_scope |
| pH-Dependent Degradation of Macrobial Environmental DNA in Water. | in_scope | in_scope | in_scope | in_scope | in_scope | in_scope |
| Environmental gradients and habitat specificity structure benthic microbial assemblages in a temperate seagrass ecosystem. | out_of_scope | out_of_scope | in_scope | out_of_scope | out_of_scope | out_of_scope |
| Evaluating Prey Availability for the Rice's Whale (Balaenoptera ricei) Based on Environmental DNA. | in_scope | in_scope | in_scope | in_scope | in_scope | in_scope |
LFM2.5以外は私の判定と同じ結果となりました。モデルのパラメーター数などで差が出るかと思っていたので予想外です。
次に2008~2026までの論文一覧について論文取得を実施後にbatch_sizeを500にして実行。事前実行の段階でGLM-4.7が判定結果を出すまでの時間が長すぎたので500本の論文判定には使わないことにしました。
# gemma
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-gemma-3n-E4B-it-Q4_K_M.jsonc
# LFM2.5
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-LFM2.5-1.2B-Instruct-Q4_K_M.jsonc
#gpt-oss 20B
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-gpt-oss-20b-Q4_K_M.jsonc
# Llama
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-Llama-3.1-8B-Instruct-Q4_K_M.jsonc
# Qwen3
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-Qwen3-4B-Instruct-2507-Q4_K_M.jsonc
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-Qwen3VL-8B-Instruct-Q4_K_M.jsonc
#gpt-oss 120B
python3 eDNA-paper-downloader/script/llama_flagger.py data/pubmed_edna_20260124.csv --config config/llama_flagger-gpt-oss-120b-Q4_K_M.jsonc
上記で得られた判定結果を視覚化・csvにまとめるスクリプトはこちらになります。
python3 eDNA-paper-downloader/script/llama_flagger_overlap.py \
results/pubmed_edna_20260124_subset-flagged-LFM2.5-1.2B-Instruct-Q4_K_M.csv \
results/pubmed_edna_20260124_subset-flagged-Llama-3.1-8B-Instruct-Q4_K_M.csv \
results/pubmed_edna_20260124_subset-flagged-Qwen3VL-8B-Instruct-Q4_K_M.csv \
results/pubmed_edna_20260124_subset-flagged-gemma-3n-E4B-it-Q4_K_M.csv \
results/pubmed_edna_20260124_subset-flagged-gpt-oss-120b-Q4_K_M.csv \
results/pubmed_edna_20260124_subset-flagged-gpt-oss-20b-Q4_K_M.csv \
--out results/pubmed_edna_20260124_subset-flagged-overlap.csv \
--plots-dir results \
--plots-prefix pubmed_edna_20260124_subset-flagged-overlap
6モデルで実行していますが、私が求める環境DNA/RNAらしい論文が7割くらいあったようです。majority_agreeは参加モデル数の「過半数以上」が同一ラベルである数を示しており、特徴が異なるものを使用してこの結果なので、複数のモデルを組み合わせると9割くらいは分類できそうな雰囲気がしますね。ちなみに、splitはall_agreeとmajority_agreeに該当せず、かつ全員不一致でもない(= 少数派がいて割れているが、全員バラバラではない)という感じです。
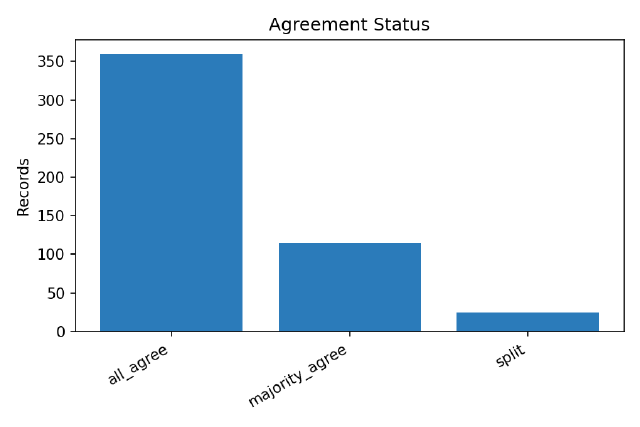
各モデルの判定結果をみてみると、LFM2.5は他とは判定結果が全然違いますね。
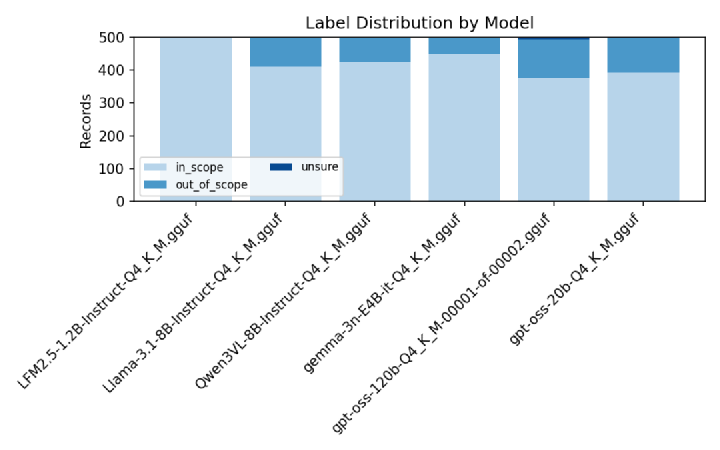
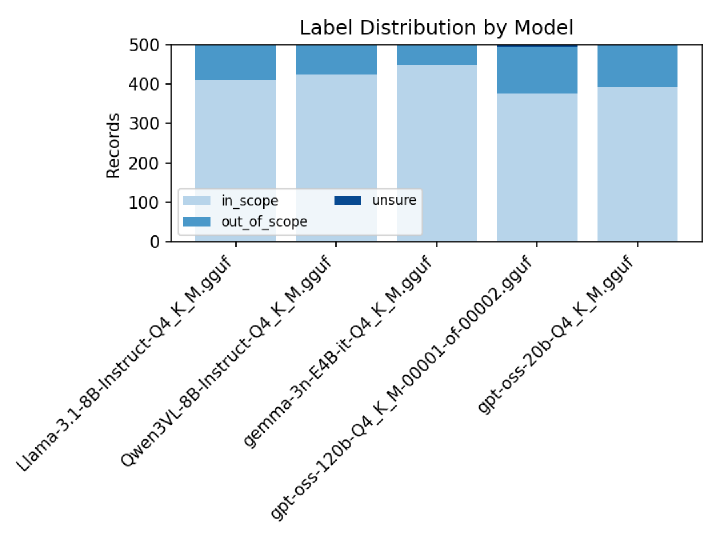
上記よりそもそもLFM2.5の結果がノイズになっているっぽいので再実行しました。splitがぐっと減って、all_agreeが増えました。LFM2.5がin_scopeとしていたものがなくなってマイナー判定がなくなった影響ですね。
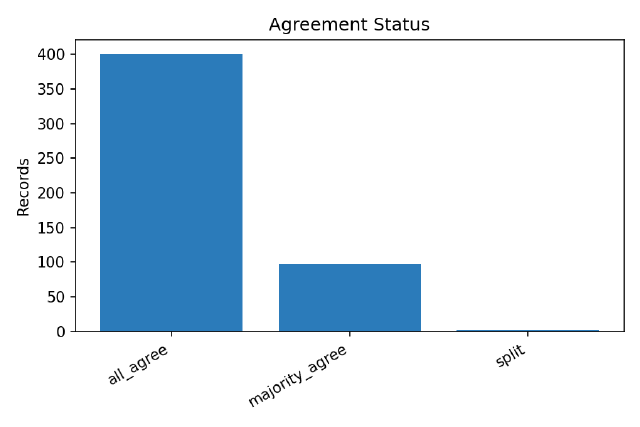
以下はそれぞれの判定結果の内訳ですが、一番モデルサイズが大きいgpt-oss-120Bが一番out_of_scopeの数が多いです。
それぞれのモデルの判定結果の一致度をまとめたヒートマップになります。
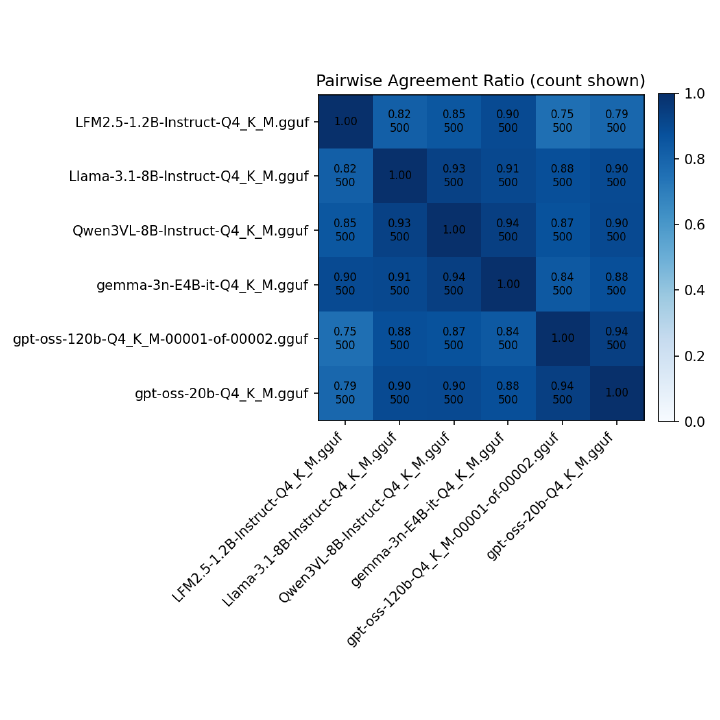
モデルサイズは違いますがgpt-oss間の相関は高いです。小さいモデル間の相関も高いですね。gpt-oss vs 小さいモデルでみるとLlama-3.1, Qwen3は8Bで時点がgemma-3nとモデルサイズに依存する結果になってそうです。
もう少しわかり易く、out_of_scope / in_scopeでモデル間の判定結果の一致性をUpSet plotで表現してみました。
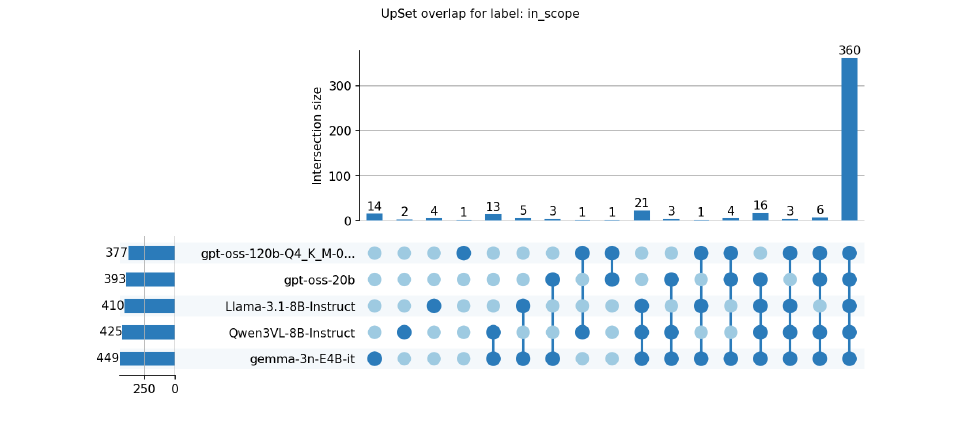
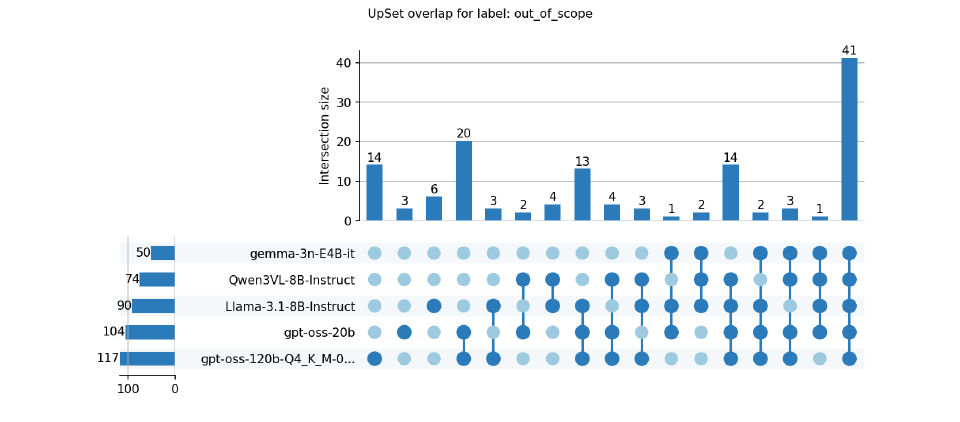
モデルサイズが大きいほうがいいような気もしますが、私のGPUのVRAMに乗るのがgpt-oss-20Bまでなのですぐ作業を終えるなら20B以下のモデルサイズのものを複数実行し、major_agreeとsplitを目視判定すればいい感じがしますね。
llama_flagger_overlap.pyが出力した*-overlap.csvの内容を確認して方針を考えてみます。ローカルLLMが身近に感じていただければ幸いです。
Note
qwen3-4Bモデルを評価に入れるの忘れてました。